

Algorithms (Methods) Used in Data Derivation
There are five effective algorithms used to derive data from the Quran. This section will explain these algorithms (methods). These algorithms and their names are as follows:
A) Letter Sequence Order Algorithm
B) Meaning-Related Formulation Method
C) Encryption Method with Prime Numbers and Factors
D) Data Encryption Method Using Letter and Word Frequency
E) Data Encryption Method Using Symmetries
A. Letter Sequence Order Algorithm
In this method, the universal word to be researched is determined. By the universal nature of the word to be researched, it is meant that this word exists in the same or similar forms in a vast majority of languages. Particularly, proper names fall into this category. For example, names like ‘Newton’, ‘Planck’, ‘Electron’, ‘Protein’, ‘Vitamin’, etc., fall into the category of universal names. A consecutive letter sequence pointing to the universal word is determined, and this letter sequence is identified within the Quran. After this letter sequence is identified, the order of this sequence within the Quran is examined. This order can be in terms of letters, words, verses, or chapters. This order can be from the beginning or the end of the reference points. There are six reference points. These points are the beginning and end of a verse; the beginning and end of a chapter; and the beginning and end of the Quran.
If the research is based on chapter count; the distance (in terms of chapter number) of the chapter containing the researched letter sequence from the beginning and end of the Quran has been used as statistical data.
If the research is based on verse count; the distance of the verse(in terms of verse count) containing the researched letter sequence from the beginning or end of the Quran has been calculated. Furthermore, the distance (in terms of verse count) of the verse containing the researched letter sequence from the beginning and end of the chapter containing this verse has been calculated.
If the research is based on word count; the distance (in terms of word count) of the word containing the researched letter sequence from the beginning and end of the verse containing this word has been calculated. Furthermore, the distance (in terms of word count) of this letter sequence from the beginning and end of the chapter containing the letter sequence has been calculated. Additionally, the distance (in terms of word count) of the word containing the letter sequence from the beginning and end of the Quran has been calculated.
If the research method is based on letter count; the distance (in terms of letter count) of the researched letter sequence from the beginning and end of the verse containing this letter sequence has been calculated. Furthermore, the distance (in terms of letter count) of the researched letter sequence from the beginning and end of the chapter containing the letter sequence has been calculated. Additionally, the distances (in terms of letter count) of the researched letter sequence from the beginning and end of the Quran have been calculated.
As can be noted, the beginnings and ends of verses; the beginnings and ends of chapters; and the beginning and end of the Quran have been determined as reference points. From these reference points, counts of letters, words, verses, or chapters are made up to the determined letter sequence.
In addition to the counts explained above, there are a few more rules. If the total word count or total letter count in the verse containing the identified letter sequence matches the subject under investigation, this is also considered a miracle. Similarly, if the total number of verses, total word count, or total letter count in the surah containing the identified letter sequence matches the subject under investigation, this is also considered a miracle.
As can be noted, only the position of a specific letter, word, verse, or chapter within the Quran is being investigated. In no way are data external to the Quran used. All analyses are conducted using the original values of the Quran, and since these counts are unique to the Quran, the perfect alignment of the data obtained from these counts with the immutable values of science is considered a miracle.It is also possible to represent the situation described here with a matrix. The Quran is a BOOK that is numbered; encoded; digitized; encrypted. If a matrix is made by denoting the positions of a selected letter from the Quran within the Quran; within the chapter; within the verse with some symbols, the following appearance emerges.
If these counting methods are to be explained as an algorithm, the following situation arises:
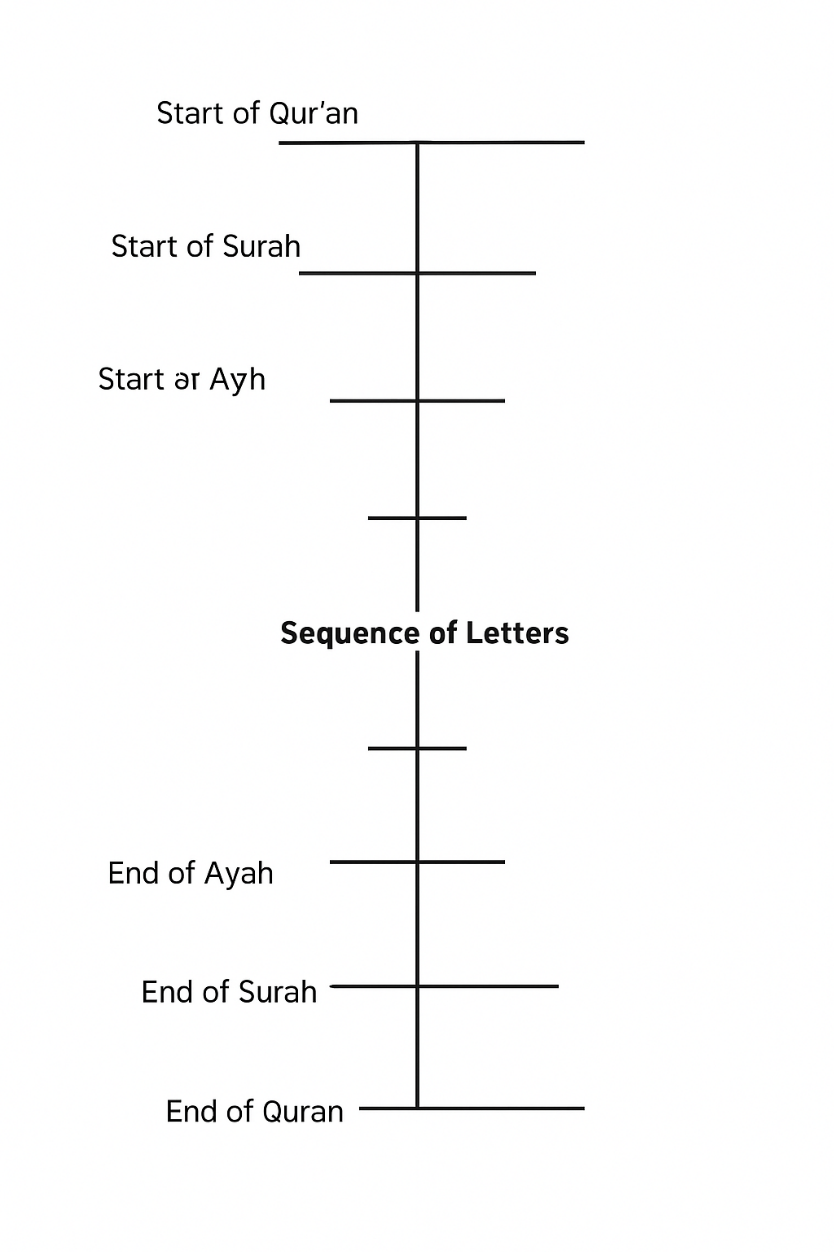
It is possible to represent the situation described here with a matrix. The Quran is a BOOK that is numbered; encoded; digitized; encrypted. If a matrix is created by denoting the positions of a selected letter from the Quran within the Quran; within the chapter; within the verse with some symbols, the following appearance emerges.
| Chapter | Verse | Word | Letter |
|---|---|---|---|
| a | w | r | p |
| b | y | t | q |
| c | z | l | f |
| d | u | h | n |
| k | o | g | |
| g | i | ||
| i | |||
| j | |||
| m | |||
| t | |||
| t-1 | |||
| g | |||
| g-1 | |||
| s | |||
| ü |





There are values that a selected letter, word, verse, or chapter from the Quran can encode or encrypt in the ways described above. In analyses, if these values match a significant value related to the subject under investigation, this match is indicated to be a miracle. The method frequently followed in analyses is of this nature. As can be noted, values such as x-1, representing the value before or after a specific order, are also used methodologically, and the reason for this is related to the methods of encrypting data. Cryptologically, both situations are reasonable and acceptable, so it is stated that the data obtained by both methods are intentional. For example, a word is selected, and it is claimed that the order of this word from the beginning or end of the Quran is a miracle. The situation where the order of the word is a miracle is quite clear and does not even need explanation. The situation where the word orders before or after the word can be a miracle can be explained as follows:
If the orders of the words from the beginning of the Quran are written sequentially, the orders of the words up to the selected word and the orders of the words after the selected word can be written as follows:
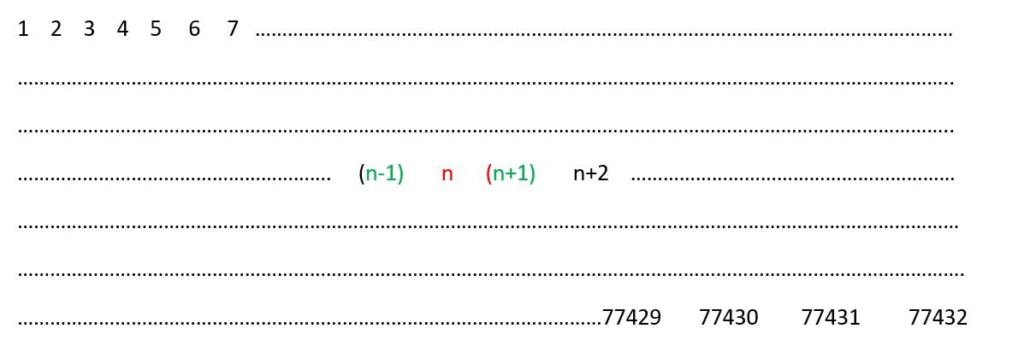
The word orders immediately adjacent to the word can be considered encoded due to their adjacency properties. The scientific counterpart of this is as follows: For example, one of the most commonly used isotopes of the carbon element in science is expressed as Carbon-14. Therefore, if a letter sequence forming the word “carbon” is found at any location, and if the order of the word to its right or left can be 14, this situation is cryptologically acceptable. The reason for this acceptability is the adjacency factor. Note that a single letter’s position can encode approximately 30 different values. Although at first glance this may seem like a somewhat flexible method, the complexion of the situation changes when we claim to have solved all the secrets of the universe with this methodology. Indeed, sometimes the value being sought represents a date like 2013; at other times, it expresses a specific cosmological value like 6.6743 * 10^-11; sometimes it denotes a constant like 1.6021; and at other times, it indicates a value like 6582. Sometimes it expresses a value like 14, while at other times it can represent a value like 232. Occasionally, a six-digit value like 326156 is detected. To be more precise, with this method, it is possible to find the charge value of the electron particle. It is possible to find the reduced Planck constant with this method. With this method, it is possible to find the total mass of the 20 amino acids. With this method, it is possible to derive many constants such as the universal gravitational constant, the Boltzmann constant, etc. If only a chapter-counting method were used, these values could not be obtained. If only a verse-counting method were used, it would again be impossible to obtain all these data together. Through such comparison, it should be understood that by employing chapter, verse, word, and letter counting methods, it is possible to find both small and large values. Therefore, for someone to ask questions like, “Why don’t you use a single method? For example, why don’t you derive data only through chapter counting?” is a very meaningless limitation. If the matter were as they say, it would not be possible to obtain large, medium, and small values. Even if it were, this would only prove that the Quran is preserved at the chapter level. However, we claim and prove that the Quran is preserved at the chapter, verse, word, and letter levels, and that all these arrangements in the Quran were carried out by divine revelation. Although the method used may seem somewhat flexible at first glance, when considered in terms of its results, it is not seen as an exaggeration at all. Indeed, we claim to have solved all the secrets of the universe with this algorithm. Data ranging from the chemical properties of elements to the masses of molecules; from the properties of subatomic particles to important scientists in history and their discoveries, etc., can be derived. Moreover, the fact that the sought letter sequence appears only once in many places, yet is precisely in the required position; exactly at the required precision, and that this occurs not once or twice but many times, shows that the Quran is perfectly arranged and preserved with divine revelation and exquisite precision.
Is there a basis in the Quran for the method of identifying letter sequences? Why did you specifically choose these words? Is there a specific rule for word selection? Can we also select any word and conduct research? Are there verses from the Quran that you can present as evidence, which motivated you to select words in this manner and research the consecutive sequence of letters forming these words? Such questions may be asked. These individuals can be answered as follows:
For example, take the word “Higgs.” The word “Higgs” originally appears as the surname of a person named Peter Higgs. Thus, it is understood that this word is universal; that is, it is pronounced the same way in all languages because it is a proper noun. The consecutive sequence of letters forming this Word- H-İ-G-S – is researched consecutively in the Quran using Arabic letters. Since the Quran is universal, what could be more natural than it pointing to things universally accepted by everyone as standards? So, does this applied method have a basis and foundation in the Quran? Yes, this topic has a foundation in the Quran, and this foundation is the Huruf-u Mukattaa (disjointed letters) found at the beginnings of chapters. Note that the letters referred to as Huruf-u Mukattaa are actually consecutive disjointed letters. For example, “Alif-Lam-Mim,” “Ta-Ha,” “Ta-Sin-Mim,” etc., are consecutive disjointed letters. In fact, the presence of these disjointed letters serves as a clue for the research conducted in this book. For instance, the word “Higgs” is broken down into disjointed letters as H-İ-G-S, and the consecutive sequence of these letters is researched in the Quran. Based on the location found, analyses related to the Higgs particle (such as its discovery date, mass value, etc.) are conducted.
When Huruf-u Mukattaa are examined, it will be seen that these letters appear as a single letter at the beginning of some chapters; as two letters at the beginning of others; as three letters at the beginning of some; as four letters at the beginning of others; and as five letters at the beginning of yet others. The letters “Nun,” “Qaf,” and “Sad” are mukattaa letters consisting of a single letter. The letters “Ta-Ha,” “Ya-Sin,” and “Ha-Mim” are mukattaa letters consisting of two letters. The letters “Alif-Lam-Mim,” “Alif-Lam-Ra,” “Ta-Sin-Mim,” and “Ayn-Sin-Qaf” are mukattaa letters consisting of three letters. The letters “Alif-Lam-Mim-Sad” are mukattaa letters consisting of four letters. The letters “Qaf-Ha-Ya-Ayn-Sad” are mukattaa letters consisting of five letters. Through these disjointed letters, Allah the Almighty has essentially given the following clues to Quran researchers: “If you break down the proper name referring to that information – for example, Higgs – into disjointed letters and research them consecutively in the Quran, you will encounter some information regarding the constants of the universe, the properties of important particles, universally accepted values, etc.” Indeed, many things accepted as standards worldwide are directly referenced by their names in the Quran. For example, the Higgs boson is indicated by the consecutive sequence of the letters H-İ-G-S. Similarly, the unit “pascal” is named after the scientist Pascal and is indicated by the consecutive sequence of the letters P-S-K-L. Although the references are generally based on the pronunciation of the word, sometimes they are based on its spelling. For example, the “ca” part in the word “pascal” is pronounced with a “k” sound, so this part is indicated by the disjointed letter “k.” The probability of some words appearing in a text can be very low. Each additional letter reduces the probability of the letter sequence appearing in the searched text – in Turkish, for example – by an average of 29 times because the Turkish language consists of 29 letters. If the probability of each letter occurring is considered equal on average, the probability of each letter occurring is 1/29.
In the Quran, when the number of letters in some words is high, it is sometimes observed that the word is referenced by its consonant letters because consonant letters, when pronounced, can be articulated with an added vowel sound using the Arabic diacritical system, effectively becoming two letters. For example, the letter “t” can be pronounced as “ta,” “te,” or “tu,” resembling two letters. In the Quran, with this wisdom, the word “neutron” is indicated by the consecutive sequence of the letters N, T, R, N. Without such a method, it is easily understandable how low the probability of the consecutive sequence of all letters of a particularly long word appearing in any text would be. Thus, it is rational for the Quran to encode in this way using consonants. So, can everything be researched in the Quran using this method? Not everything can be researched this way. If a generalization is made based on the data we have identified:
It is likely that proper names are referenced. For example, names like Higgs, Pascal, and Edwin Hubble. Similarly, it is also probable that the name of a specific category is referenced in this way. For example, vitamins are a category, and this category is referenced through the letters “V-T-M-N.” Leptons are a group of particles, and this group is referenced through the letters “L-P-T-O-N.” Note that when a word is broken down and arranged in this way, it immediately brings to mind the consecutive sequence of mukattaa letters. In our view, the data presented in this book are one of the best interpretations that can be made for Huruf-u Mukattaa. If the interpretations made about mukattaa letters are examined, it will be noticed that these interpretations are not very fitting for the grandeur of the Quran. Although some words are not universal, if they are known by most countries worldwide, it is likely that they are also referenced. For example, the word “retina,” although it has a specific equivalent in Arabic, is pronounced as “retina” in almost all world languages, so in the Quran, the word “retina” and the number of photoreceptors in the retina are indicated through the letter sequence of retina. During research, the sequence of the word may occur from right to left or from left to right. Both cases fall into the miracle category, and a considerable number of encodings have been made in both directions in the Quran. Since writing in world languages is generally from right to left or left to right, the occurrence of bidirectional encodings in the Quran is consistent with its universal nature. Additionally, bidirectional encoding is much more complicated and is generally not seen in works written by humans. Therefore, bidirectional encoding also shows that the Quran contains knowledge beyond human capability. Apart from these explanations, sometimes when the letters forming a word are repeated in multiple positions, certain reasons become preferences in analysis. For example, reasons such as the first occurrence of these consecutive letters, the last occurrence, or the most frequent occurrence can be grounds for preferring to analyze that location. In this book series, we have established rules to a level where generalizations can be made. We can interpret the Quran within the limits of our capacity. Only Allah the Almighty knows the full interpretation of the Quran, and it is only He who teaches the interpretation to His servants as much as He wills. Therefore, those who, despite seeing very serious miracles in this book, expect the same exact method to be used in every analysis like a carbon copy should know that they are not sincere in their expectations. In science, can you calculate everything with a single formula that you expect us to calculate all data with a single method? Do you calculate the universal gravitational constant and the Boltzmann constant with the same formula that you expect us to derive these two constants with the same method? Still, if these people are fair, they will notice that many data in this book are derived with perfectly similar methods; but if they succumb to their pride, the losers will be themselves.
A branch of the letter sequence order algorithm is the method we call the “matrix” method. In this method, the order of the location where the identified letter sequence is found is also examined, but in matrix form. For example:
The positions of the verses in the Quran are written in the format Chapter number: Verse number = (x:y). For example, the verses of Surah Al-Baqarah can be written in this format:

Therefore, there are also miracles in the arrangement of the chapter and verse numbers of the Quran in matrix format. In the Quran, a coordinate value is sometimes indicated. As is known, coordinate values are expressed in degrees and minutes. In perfect harmony with this, the position of any verse in the Quran is also expressed by its chapter number and verse number. For example, the 2 nd chapter’s 125 th verse is expressed as 2:125. In the Quran, while verse 2:125 refers to the Kaaba, the latitude coordinate of the Kaaba is 21° 25′. As can be seen, the values indicating the position of this verse encode the latitude value of the Kaaba as a matrix. That is, the degree and minute values are obtained by combining the chapter and verse numbers side by side. This method is direct and involves no external interference. By simply bringing together the values of the verse’s position, a datum with multiple parameters is indicated. We have generally named this method the “matrix method.” As is known, in linear algebra, data are encoded within matrices.
The dimensions of matrices can vary. While sometimes a matrix consists of two columns and one row, encoding two data points; other times, a matrix consists of two columns and two rows, encoding four values. For example, the mass of the deuteron nucleus is expressed as 3.343 × 10⁻²⁷ kg. In a verse where the word “deuteron” is encoded, there are 3 words in the verse before the word “deuteron,” and 343 letters in the chapter before the letters of “deuteron.” Additionally, the verse number containing the word “deuteron” is 10, while the verse containing the word “deuteron” consists of 27 words. Thus, the value 3.343 × 10⁻²⁷, which is the mass of the deuteron nucleus, is encoded as a four-value matrix using the most fundamental data of the verse. It falls upon Quran researchers to notice these details.
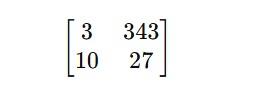
Note: The mass of the deuteron can also be expressed as 3.344 × 10⁻²⁷ kg. In this case, the 344 th letter from the beginning of the chapter exactly corresponds to the letter ‘d’ of the word “deuteron.” These examples provided are real examples existing in the Quran. Hypothetical examples are not given.
Sometimes, in verse 18:39, where the word “neutron” appears, consistently with this, the ratio of the neutron’s mass to the electron’s mass is calculated to be approximately 1839. Thus, by combining the chapter and verse numbers side by side, a matrix containing two data points approximately indicates the ratio of the neutron’s mass to the electron’s mass. Therefore, the matrix method is used in many places in the Quran. The relationship between the matrix method and the disjointed letters (mukattaa) was explained in the section “Evidence and Signs Related to Numerical Miracles.” Readers can also refer to that section.
Additionally, a list will be provided here regarding which letters in the Latin alphabet can represent Arabic letters based on the diacritical marks they can take. The purpose of providing this list is to make the method used in the book somewhat accessible even to those who do not know Arabic at all. There are details to the situations presented in this list, and these details were explained with examples throughout the book where appropriate, so that the table does not appear too complex. To give a few examples: the letter و can be transliterated into Latin languages as w, v, u, ü, o, ö. Another example is the issue of transliterating the letter ‘p’ through the letter ‘b’ ب due to the absence of the ‘p’ sound in Arabic. Such technical details are known even by those with intermediate knowledge of Arabic; however, brief explanations are still provided without issue. For instance, the sound ‘g’ can be transliterated in Arabic through the letters ج, ق, or غ. For example, the letter ث can be transliterated into Latin languages as ‘s’ or ‘th’. For example, the letter ش can be transliterated into Latin languages as ‘ş’ or ‘sh’. For example, the letter ق can be transliterated into Latin languages as ‘Q’, ‘K’, or ‘G’. For example, the letter ا (alif) in Arabic can be transliterated as ‘a’ or ‘e’, and with diacritical advantages, as ‘u’, ‘ü’, ‘ı’, or ‘i’. Additionally, the letters ي, ئ, and ى each represent ‘y’ and ‘ı’, ‘i’, ‘e’ in unvocalized writing. Since the original script of the Quran is unvocalized and our Quran methodology prioritizes the visual representation of letters, the transliteration of these letters into Latin languages is primarily analyzed through the letters ‘y’, ‘ı’, and ‘i’.
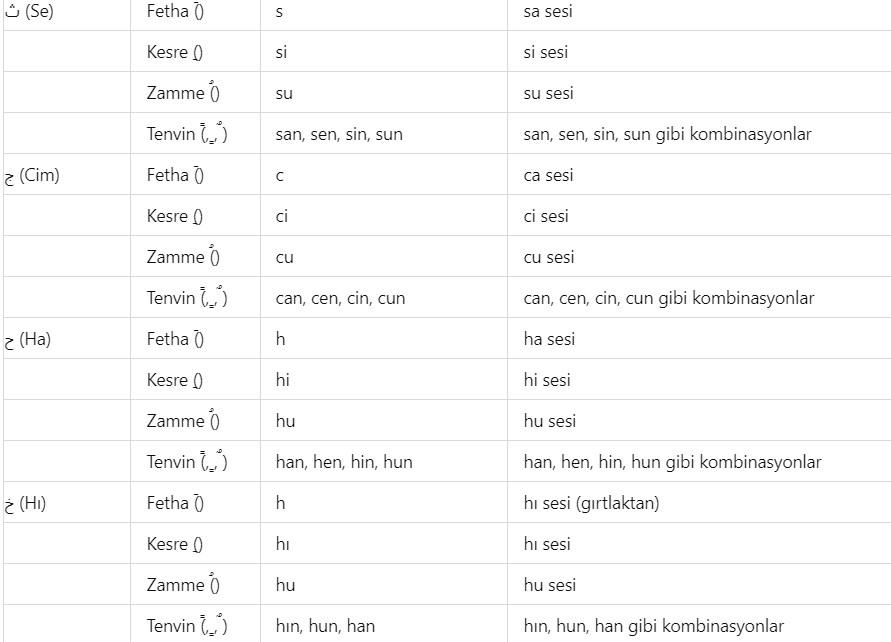
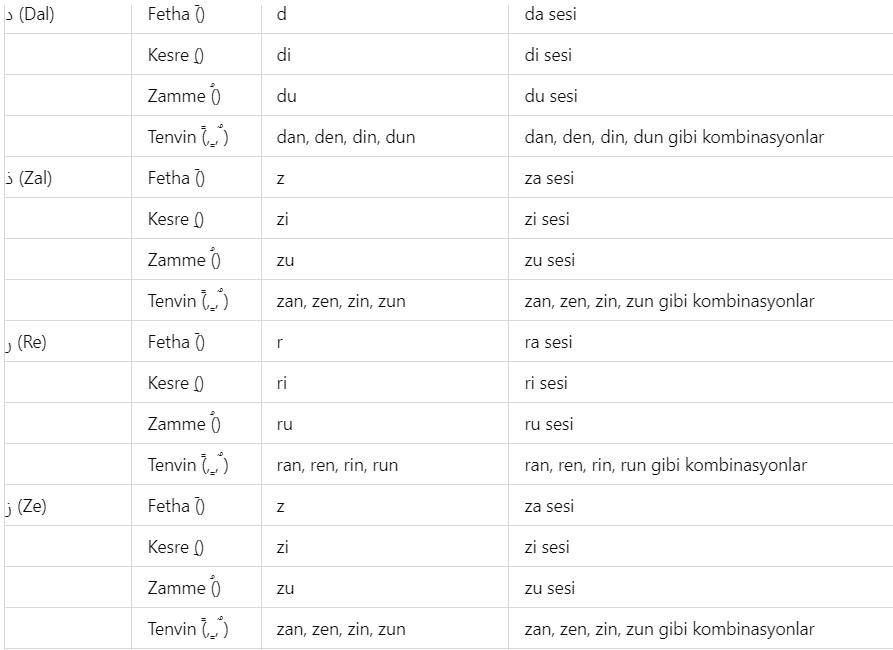
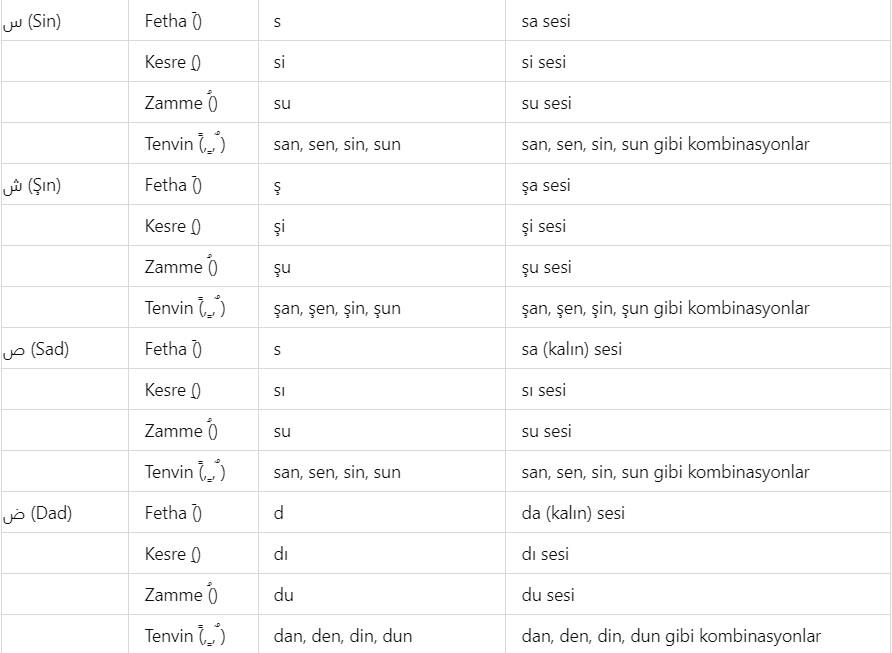

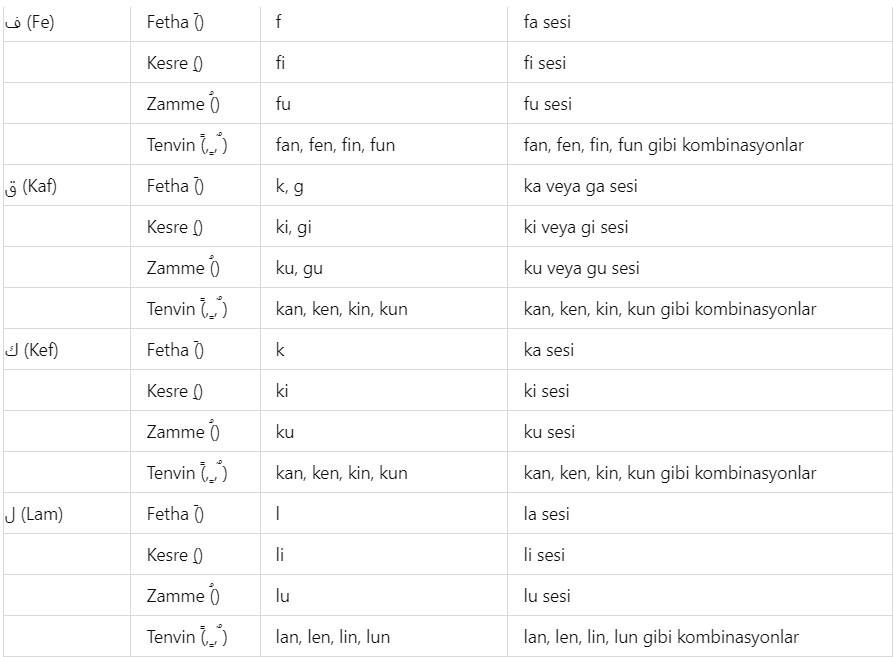
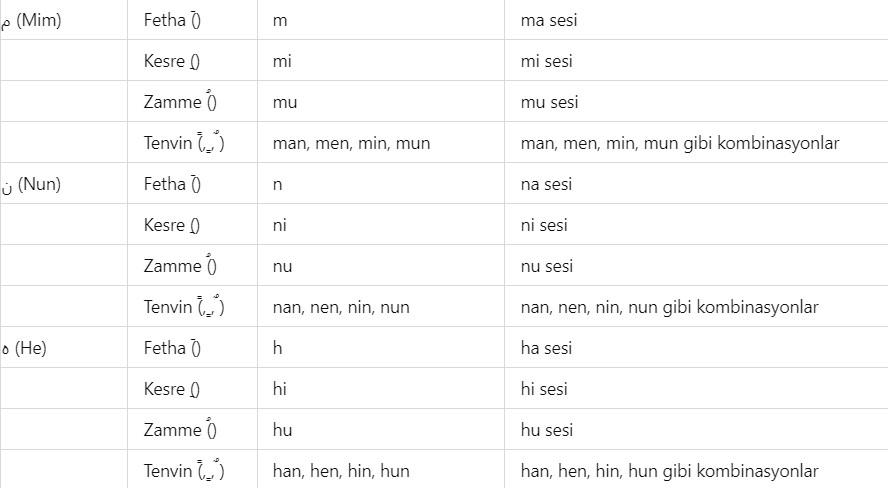
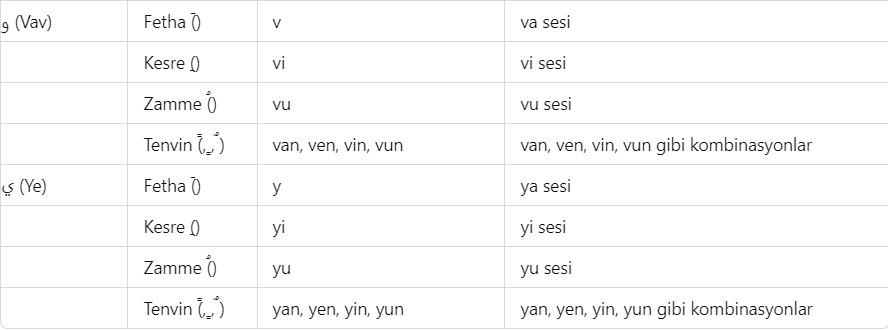
Diacritical marks (harekes) in an Arabic text facilitate the encoding of a word more easily. There are thousands of wisdoms in the revelation of the Quran in Arabic, and one of these wisdoms is the advantage of Arabic’s diacritical system. Additionally, in the Arabic language, it is possible to express profound meanings with few letters. As is known, the Quranic text was written without diacritics. Diacritics were added above or below the letters in the Quranic text in later periods to prevent people from misreading the Quran—that is, to preserve the correct pronunciation of the Quran.
When researching a specific sequence of letters in the Quranic text, analyses are conducted by considering all possible diacritical marks that the letter could represent. For example, suppose we encounter a letter sequence like ا س. This sequence of letters, with the advantages of Arabic diacritics, can encode letter sequences such as is, es, as, us, üs, os, ös, ise, isa, isu, isse, issu, issa, esse, essu, essa, asse, assu, assa, usse, ussu, ussa, osse, ossu, ossa, etc.
While the selected letter sequences in the Quranic text can be read in only one form, the unvocalized form of this sequence can encode many letter sequences. This is a very unique advantage of the Arabic language, and only a few languages possess this advantage. This fact alone is sufficient to understand the wisdoms behind the revelation of the Quran in Arabic. Indeed, the Quran was revealed by Allah, the possessor of infinite knowledge, and it is expected that this Book encompasses infinite knowledge. At the same time, it is also expected that the text is not excessively long, so that people can easily memorize and analyze it. When many such factors are considered together, the Arabic language has magnificent advantages in terms of its capacity to bear the Divine Word.
Returning to the situation described above, since the Quranic text is written without diacritics, a sequence of letters can encode a vast number of letter sequences by using diacritics such as fatha, kasra, damma, shadda, and even tanwin. This advantage is so significant that to explain it, an analogy can be drawn with the superiority of qubits in quantum computers over the concept of bits in supercomputers and standard computers:




As can be seen, the concept of qubits in quantum computers holds a significant advantage over the concept of bits in normal and supercomputers. While classical computers operate with two states (1 and 0), quantum computers utilize the superposition of these two states, resulting in 2n possible states.
An analogy can be drawn with the Arabic language: Depending on the diacritical marks a letter can take (such as fatha, kasra, damma, shadda, tanwin), the number of combinatory possibilities (that can be encoded or encrypted) offers an advantage over a typical language without such a system. This increased complexity enhances cryptographic potential, similar to how qubits expand computational possibilities.
1. Letter Encoding in a Typical Language
In a typical language, we assume a letter is represented in only one way. For example, “A” simply represents itself and carries no additional information. In this case, a single letter corresponds to one unit of encoding. That is, a word consisting of n letters carries only n units of information.
2. Letter Encoding in Arabic
In Arabic, each letter can be enriched with different diacritical marks:
- Fatha (upper line): Indicates an open vowel sound.
- Kasra (lower line): Indicates a thin vowel sound.
- Damma (waw-like upper mark): Produces a rounded vowel sound.
- Shadda (repetition mark): Indicates emphasis or gemination of the letter.
- Tanwin (double-dot marks): Used with nouns and in specific grammatical cases.
In this case, each letter can be enriched with 5 different diacritical mark combinations. This means a single letter in Arabic has 5 times more encoding possibilities.
Note: Not every sequence of letters results in 5n combinations. The 5n number of combinations represents the theoretical maximum. In practice, this many combinations cannot occur because meaningful word encoding imposes numerous constraints, such as minimum letter requirements and grammatical rules. Nevertheless, the Arabic language still offers a significantly higher number of combinations compared to other languages.
The reason for explaining all these points is as follows:
In the QURANIC text, a word is generally recited in a single way (though some recitations may allow for multiple forms). However, the combinations that the letters forming the word can encode follow a 5n pattern based on the number of letters. At the moment of recitation, all these combinations collapse into a single recited form. Yet, from a cryptological perspective, the sequences of letters that a word can encode contain numerous combinations.
This situation reminds the collapse of the wave function in quantum physics. That is:



Yes, although the recitation of the Quranic text collapses into a single form during reading – reminding the collapse of a wave function – the potential combinations that the text can encode consist of numerous possibilities, reminding the quantum superposition states.
After explaining these points, the following question some might ask is meaningless:
“Why do you take a letter sequence as ‘us’ when it is recited as ‘is’ in the Quran, for example?”
If they ask this, we tell such individuals that they need to study topics like cryptography and quantum superposition, because these subjects are precisely the key to understanding the cryptography in the Quran. Since the Quranic text is written without diacritics, the letters it can encode closely reminds quantum superposition states. However, at the moment of recitation, all these possibilities collapse into a single one, reminding quantum wave function collapse. With certain recitation advantages, it may collapse into a few possible readings, but the main point here is that the number of letter sequences the text can encode contains far more possibilities than the way it is read.
Of course, after these explanations, some might think that the data we present is an advantage of the Arabic language rather than the Quran. To such individuals, we say: Go ahead, scan all Arabic books and derive the data we presented in the analysis of the cesium element. Although Arabic has its advantages, the Quran possesses a unique super-advantage independent of the benefits provided by the Arabic language, because the encodings in the Quran were specifically arranged by DIVINE design. In ordinary Arabic texts, some letter sequences may occur unintentionally or by coincidence, but it is abundantly clear that the occurrences in the Quran are intentional. This is especially evident in letter sequences that appear only once or a few times in the Quran. For example, the arsenic letter sequence appears only once, but it appears exactly where it should. Similarly, the ‘Parsec’ letter sequence appears only once, yet it enables the derivation of a value with perfect precision. Likewise, the letter sequence encoding the element Einsteinium appears only once, yet it is positioned exactly where it should be. Similarly, the letter sequence encoding the cesium element appears only twice in the Quran. These examples can be multiplied, but this much explanation is sufficient.







Leave a Reply